 Taxonomien und Folksonomien – Tagging als neues HCI-Element
Taxonomien und Folksonomien – Tagging als neues HCI-Element
Matthias Müller-Prove in i-com (1)2007
Zusammenfassung. Community-Portale bieten immer häufiger kollaborative Tagging-Systeme zur zusätzlichen Auszeichnung ihrer Informationen an. Damit etabliert sich gerade ein neues Interface-Element, das das Potenzial zu einem erweiterten Umgang mit den Daten der digitalen Welt an sich hat. Dieser Artikel beschäftigt sich mit den interaktiven Aspekten des Taggings, sowie mit der semantischen Ebene in Abgrenzung zum etablierten Wissensbegriff.
Summary. Tagging is a very popular element on social community websites that fosters user participation and their contributions to add meaning to the data. It has the potential to become a new element to interact with data in the digital world in general. This paper discusses the interactive properties of tagging systems, and the semantics of tagging with respect to the well established notion of knowledge.
Einleitung
Tagging als neues Element zur Dateneingabe im Interface-Design und Tag-Wolken als Gestaltungselement der Datenvisualisierung auf Community-Websites der zweiten Generation sind en vogue. Im Gegensatz zu Ordnern und Dokumenten, die noch vor zehn Jahren in der Desktop-Welt die dominierenden Container für Informationseinheiten darstellten, sind die neuen interaktiven Interface-Elemente Web-basiert und unterstützen die Anwender bei der Strukturierung der Informationen im Internet. Der Ansatz ist weit weniger rigide, als die hierarchischen Ordnerstrukturen und ist deshalb eine angemessenere Antwort auf die Informationsflut des Netzes, als es die direkt-manipulativen Methoden der Schreibtisch-Methaper je sein könnten. Insbesondere bündeln sie die Aktivitäten der einzelnen Community-Mitglieder zu einem gemeinsamen Vorgehen, so dass ein kollaborativ dynamischer Mehrwert entsteht.
Dieser Artikel widmet sich den interaktiven Aspekten des Taggings im Web-Design und vergleicht die semantische Ebene mit dem klassisch-hierarchischen Taxonomie-Ansatz.
Die Ordnung der Dinge
Seit Alters her sucht der Mensch die Dinge, die ihn umgeben und bewegen zu benennen, zu sortieren und zu klassifizierten. Dabei hat sich ein Wissensbegriff gebildet, für den laut David Weinberger (Weinberger 2006) sieben Eigenschaften gelten.
- Wissen ist für alle gleich.
- Wissen ist universell, das heißt es gibt nicht zwei verschiedene Wissen.
- Wissen ist unabhängig vom Individuum, das es formuliert.
- Wissen ist unvergänglich.
- Wissen ist geordnet.
Insbesondere der letzte Punkt führt häufig zu großen hierarchischen Strukturen, in die die Dinge der Welt einsortiert werden. Dinge sind belebt oder unbelebt. Die belebten sind entweder Pflanzen oder Tiere. Bei den Tieren gibt es Wirbeltiere und wirbellose Tiere. Zu Erstgenannten gehören die Reptilien, die Vögel und die Säugetiere. Bei den Vögeln kommen in der nächsten Ebene die einzelnen Arten von Adler bis Zeisig. Andere Pfade der Taxonomie mögen noch tiefer verschachtelt sein, ehe man zu den konkreten Dingen an den Blättern der Baumstruktur kommt.
Je nach Anwendungsfall sind die Taxonomien mehr oder weniger detailreich. Es wird aber nicht in Frage gestellt, dass im Prinzip alle Taxonomien das gleiche universelle Wissen beschreiben.
Digitale Schreibtisch-(Un-)Ordnung
Das Erbe dieser Tradition findet sich auch in der Ausgestaltung der Desktop-Metapher wieder, wo die Ordnerhierarchien eine direkte Übertragung des Taxonomie-Konzepts in die virtuelle Welt des PCs sind. Daher müssen Dateien einen eindeutigen Platz in der Ordnerhierarchie einnehmen, was zu teilweise absurden und nicht mehr durchschaubaren Strukturen führt. Die Einführung von à proposn auf Dateien und Ordner an einer anderen Stelle in der Dateistruktur (genannt Alias beim Macintosh, Verknüpfung unter Windows und Link auf den Unix/Linux/Solaris Betriebssystemen) ist dabei als unzureichender Versuch anzusehen, die starre Einordnung der digitalen Objekte aufzuweichen.
Hypertext und World Wide Web
Es geht auch anders. Ted Nelson hat Mitte der 1960er Jahre den Hypertext-Begriff eingeführt. Ausgehend von seiner Überlegung „Everything is deeply intertwingled“ verwirft er die lineare Ordnungsstruktur bei der Erstellung von Texten und propagiert die freie Verknüpfung zu nicht-linearen und nicht-hierarchischen Hypertexten. Ideen und logische Informationseinheiten müssen nicht mehr einen eindeutigen Platz in der Ordnung einnehmen – sie können vielmehr von anderen Hypertext-Knoten gleichberechtigt referenziert werden und stehen somit quasi an mehreren Orten gleichzeitig zur Verfügung.
1989 hat Tim Berners-Lee dann mit der Entwicklung des World Wide Web die Ideen von Nelson mit dem Internet (weltweiter Datenaustausch zwischen vernetzten Servern) und einer Abstraktion des lokalen Dateisystems (Universal Resource Identifiers identifizieren eindeutig eine Datei auf einem Server; aus den URIs wurden in den folgenden Jahren die Uniform Resource Locators (URLs).) verbunden. Die Zahl der Web-Server nahm seither explosionsartig zu, so dass ein weltumspannendes Geflecht mit bislang mehr als 100 Millionen Web-Servern gewachsen ist.** Laut Hoppes’ Internet Timeline waren im November 2006 mehr als 101.435.000 Web-Server online. (Zarkon 2006)
In diesem digitalen Universum sind Ordnungs- und Orientierungshilfen notwendiger denn je. Deshalb werden im Folgenden Tagging-Systeme diskutiert, die in den letzten Jahren populär geworden sind.
Tagging
Tags sind eine Form von Metadaten, die der Anwender bestimmten Entitäten der elektronischen Welt frei zuordnen kann. Anhand eines ersten Beispiels wird die Funktionsweise von Tags bei der Verwaltung von Bookmarks vorgestellt.
Social Bookmarking
Browser-Applikationen bieten die Funktion, für eine Webseite die zugehörige URL zu merken und sie in der Menüstruktur für späteren direkten Zugriff anzubieten. Dabei bedienen sie sich einer hierarchischer Listenstruktur mit selten mehr als zwei Ebenen.
Dieser Mechanismus ist aus mehreren Gründen ungeeignet für die sinnvolle und dauerhafte Unterstützung des Anwenders beim Surfen durch das World Wide Web. Die Listen dieser Lesezeichen werden schnell unübersichtlich und veralten zum Teil, da die Webseiten nach einiger Zeit nicht mehr existieren oder ihr Inhalt stark verändert wurde. Außerdem kommt es zu Synchronisationsproblemen, wenn der Browser gewechselt wird oder gar gleichzeitig mehrere Browser oder verschiedene Computer benutzt werden.
Für eine bessere Ordnung und für die Unabhängigkeit von einem konkreten Browser bieten Web-basierte Dienste eine Alternative. Dabei werden die Bookmarks an ein persönliches Konto – beispielsweise bei del.icio.us** Als der Webdienst del.icio.us (http://del.icio.us) 2005 von Yahoo! übernommen wurde, war die Zahl der Benutzer in den zwei Jahren seit Gründung auf 300.000 angewachsen. – geschickt und zusätzlich mit einem oder mehreren Schlagworten versehen.
Da dies nun keine Funktion mehr ist, die vom Browser direkt mit einem Kommando unterstützt wird, bietet del.icio.us entsprechende Java-Skript-Erweiterungen an, die im Browser installiert werden. Ein Mausklick auf die Funktion „post to del.icio.us“ übergibt dann die aktuelle URL an ein Webformular, in das die Schlagworte eingetragen werden können (vgl. Bild 1).
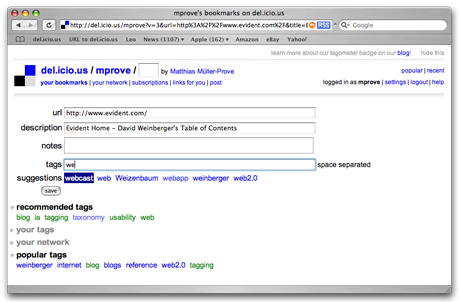
Bild 1: Erfassung einer Webseite beim Social Bookmarking Dienst del.icio.us. Während der Eingabe der Tags werden auf Basis des eigenen Vokabulars Wortvervollständigungen angeboten, sowie „Popular Tags“ vorgeschlagen, die von anderen Community-Mitgliedern bereits für diese Webseite zugewiesen wurden.
Die Schlagworte sind die Tags (engl. für Etikett) und haben mehrere Funktionen. Wenn man auf der Seite von del.icio.us einen der Tags auswählt, werden alle unter ihm klassifizierten Webseiten aufgelistet.
Zweitens bestimmt man durch die Vergabe von Tags für Einträge nicht einen eindeutigen Ort in einer Ordnerstruktur. Statt dessen bilden Tags eine nicht-hierarchische Ordnung über den Dingen, da eine Website ohne weiteres mehreren Tags zugeordnet sein kann. Damit entfällt der rigide Zwang zur eindeutigen Ablage.
Wenn die Tagging-Daten, wie im Falle von del.icio.us öffentlich sind, ergeben sich weitere kaskadierende Effekte. Nutzer mit gleichen oder ähnlichen Interessen werden sichtbar (Netzwerke entstehen). Und die eigene Recherche wird durch andere Teilnehmer unterstützt.
Tagging im Allgemeinen
Das Einsatzgebiet vom Tagging beschränkt sich nicht nur auf Social Bookmarking. Die Tags von Google Mail (dort „Labels“ genannt) und Xing dienen der Ordnung der eigenen Mails, respektive des persönlichen Kontaktnetzwerkes, da sie nicht für andere Anwender der Dienste einsehbar sind. Technorati verwendet Tags, um Blog-Einträge zu sichten. Flickr hat das System für Bilder eingeführt, YouTube für Videos, Netflix in den USA für einen DVD-Leihservice. Last.fm adaptiert das System für Musik. Die Liste ließe sich beliebig fortführen und die genannten Firmen sind auch nur die jeweils prominentesten Vertreter ihrer jeweiligen Sparte.
Der soziale Aspekt des Taggings kommt dadurch ins Spiel, dass die Web-Applikationen als Nachfahren der Client-Server-Architektur ständig die empfangenen Daten der Anwender miteinander verknüpfen können. Ein Foto, das Anja mit dem Tag „Eiffelturm“ attribuiert hat, wird für Bodo auffindbar, indem er nach Objekten sucht, die mit dem Tag „Eiffelturm“ versehen wurden. Tags können also auch genutzt werden, um Dinge zu finden, die man selbst noch nicht kennt.
Tag-Wolken
Über die Häufigkeitsverteilung aller Tags ergeben sich die so genannten Tag-Wolken (Tag Clouds). Dabei werden die Tags, die am häufigsten vergeben wurden, in einer alphabetischen Liste angeordnet. Zeichengröße und gelegentlich auch Farbkontrast werden genutzt, um die oft benutzten Tags zu betonen und sie von von den selteneren Tags abzuheben. Das Ergebnis ist einer Datenvisualisierung, die einen schnellen Überblick über die Themen gibt.

Bild 2: Die Tag-Wolke der Online-Bilderverwaltung von flickr (flickr.com/photos/tags/). Dargestellt sind die 145 populärsten Tags, die insgesamt auf flickr vergeben wurden.
Wird in die Kalkulation noch einen Zeitfaktor eingerechnet – kürzlich vergebene Tags erhalten einen höheren Wert – werden die aktuellen Themen zusätzlich betont und man erhält eine Visualisierung der Themen, die im Moment besondere Beachtung finden. Dies geschieht insbesondere bei Technorati, um den Besuchern der Website einen schnellen Eindruck zu geben, welche Themen aktuell in der Blogosphäre behandelt werden.
Folksonomy
Der Neologismus „Folksonomy“ wurde erstmals 2004 auf einer Mailingliste des Information Architecture Institute von Thomas Vander Wal verwendet (Merholz 2006). Es ist eine Wortneuschöpfung aus dem englischen „Folk“ und „Taxonomy“ – quasi die pluralistische Stimme des Volkes, die durch die Tagging-Aktivitäten der Einzelnen eine neue Sinnebene erzeugt. Es gibt keine Experten, die die Bedeutung und Ordnung der Dinge festlegen, sondern einen dezentralen, unkoordinierten, sozial-kumulativen Effekt, der zu den oben angeführten Ergebnissen führt.
Ein Vergleich mit den eingangs vorgestellten Wissenseigenschaften zeigt, dass die auf Tagging basierende Sinnebene nicht mit Weinbergers Darstellung in Einklang zu bringen ist. Tags sind individuell. Sie müssen nicht widerspruchsfrei vergeben werden – nicht einmal innerhalb des Bereichs eines einzelnen Nutzers. Und Tags sind nicht geordnet. Es sind simple Tupel zwischen dem Bezeichnenden, dem Bezeichneten, dem Tag und ggf. der Zeit. Weitere Dimensionen sind denkbar und führen im Falle von geografischen Koordinaten zum so genannten Geotagging.
Trotzdem ist der Vergleich mit Taxonomien zulässig, da Tags auch Semantik induzieren. Die Folksonomy ist also genau wie die Taxonomie eine bedeutungstragende Ebene.
Vokabular
Wenn für die Vergabe der Schlagworte bestimmte Regeln gelten, spricht man von einem kontrollierten Vokabular. Insbesondere das Bibliothekswesen hat in dieser Hinsicht eine lange Tradition. Es zieht beispielsweise die singulare Nominalform den gebeugten Formen vor. Und unter Synonymen wird ein Begriff besonders ausgezeichnet, der als Schlagwort vergeben wird, wohingegen die anderen ungenutzt bleiben und allenfalls im Index auf den Hauptbegriff verweisen. Dieses Vorgehen ist dort sinnvoll, wo eine größere Gruppe auf die Verschlagwortung oder Indexierung angewiesen ist, um Dokumente oder sonstige Artefakte aufzufinden, für die es eine etablierte Ordnung gibt.
Da Tagging-Begriffe ad-hoc, nach persönlichem Geschmack und Sprachverständnis vergeben werden, hat man es hier mit einem unkontrollierten Vokabular zu tun. Ein Abgleich mit einem Regelwerk oder Thesaurus würde einen Mehraufwand bei der Vergabe der Tags bedeuten, dessen Nutzen für den Anwender nicht unmittelbar einsichtig wäre. Selbst orthographische Fehler verzeiht das System, wie eine Suche nach „Eifelturm“ in flickr zeigt.
Semantik
Der Mechanismus, über den die Semantik induziert wird, ist die Sprache, die als der einzige gemeinsame Nenner der voneinander unabhängigen Akteure fungiert. Obwohl jeder bei der Festlegung seiner Tags völlig frei ist, besteht doch die Tendenz mindestens für einen selbst sinn-volle Zeichenketten zu wählen, damit man später über das Wiedererkennen und Anklicken dieser Begriffe das getaggte Objekt wieder findet.
Das gemeinsame Sprach- bzw. Wortverständnis wird durch einen sozialen Rückkopplungseffekt noch verstärkt. Die Tags des jeweiligen Systems sind öffentlich, so dass man durch Suchen leicht feststellen kann, ob ein Tag schon verwendet wird oder ob dafür bereits eine bestimmte Schreibweise eingeführt wurde. Wie soll man beispielsweise ein Foto aus New York taggen? Da ein Leerzeichen oft zur Trennung der Tags genutzt wird, sind „New York“ eigentlich schon die zwei Tags „New“ und „York“. Man kann sich vorstellen, das sich hinter den beiden Tags jeweils sehr allgemeine Fotos ansammeln würden – die gesuchten Fotos aus New York wären sicherlich nicht an erster Stelle dabei. Also empfiehlt sich die Verwendung eines spezifischen Tags, das diese Mehrdeutigkeit nicht besitzt. Ob man dann lieber „newyork“, „newyorkcity“ oder „nyc“ benutzen sollte, hängt von der bisherigen Vergabe der Tags ab. Das Tag mit mehr Treffern ist vorzuziehen, da dort mehr Aktivität anderer zu erwarten ist. In Bild 2 ist diese Unsicherheit bei der Tag-Vergabe für Bilder aus New York sehr gut zu erkennen. Für den Einzelnen ist die Entscheidung jeweils irrelevant. Mit einer geschickten Wahl der Tags, kann man jedoch die kollaborativen Netzeffekte stimulieren.
Dieser Rückkopplungseffekt verstärkt sich um so mehr, je mehr Leute bestimmte Tags verwenden. So können sich gewisse Konventionen für eine Tagging-Plattform etablieren, die aber unter einer andern Plattform nicht mehr gelten müssen.
Insgesamt bildet sich ein dynamisches System, das bei allen Unzulänglichkeiten und Widersprüchen dennoch erstaunlichen Nutzen bringt.
Web Zwei Null
Im Oktober 2004 hat eine von Tim O’Reilly ausgerichtete Konferenz unter dem Titel „Web 2.0“ stattgefunden.** Der Name „Web 2.0“ wurde von Dale Dougherty, einem von Tim O’Reillys Mitarbeitern kreiert (Lotter 2007). Der Begriff ist in den letzten beiden Jahren sehr in den Mittelpunkt der Aufmerksamkeit gerückt. Dass die Grundprinzipien aber bereits viele Jahre davor im Internet und World Wide Web angelegt waren, macht den Begriff aber eigentlich irreführend. Zusammenfassend versteht man unter Web 2.0 die folgenden Eigenschaften (O’Reilly 2005):
- Das Web und alle damit verbundenen Geräte sind eine globale Plattform für wiederverwendbare Daten und Services.
- Daten werden aus allen möglichen Quellen miteinander gemixt; insbesondere auch die vom Anwender erzeugten Daten.
- Daten und Software unterliegen einer stetigen und häufigen Aktualisierung.
- Die Interaktionselemente sind ausdrucksstark und performant.
- Die Systemarchitekturen berücksichtigen die aktive Teilnahme von Anwendern und fordern sie zu Eingaben auf.
Es stellt sich die Frage, warum das Tagging und die damit einhergehende Bedeutungsebene der Folksonomy gerade heute so stark nachgefragt wird. Das Prinzip des Taggings ist nämlich nicht erst für die Webdienste del.icio.us und flickr erfunden worden. Bereits 1987 boten die DOS-Programme Lotus Agenda und Lotus Magellan – für Personal Information Management und Dateiverwaltung – Tags zur zusätzlichen Auszeichnung der Daten an. Und Alan Cooper propagierte 1995 ein „Attribute Based Retrieval“ als zusätzliche Ebene zum Dateisystem, in der der Anwender Dokumenten nach Bedarf Attribute zuordnen können sollte. Die Attribute sollten dann dazu genutzt werden, alle so ausgezeichneten Dokumente aufzurufen (Cooper 1995, S. 106).
Auf dem Desktop sind diese Ansätze bis heute kaum realisiert. Das Web ist aber inzwischen derart gewachsen, dass hier verstärkt nach Ordnungsmöglichkeiten gesucht wird, die der Komplexität angemessen sind. Mit dem Einsatz von Ajax** Jesse James Garrett prägte AJAX als Abkürzung für Asynchronous JavaScript and XML. Da Garrett inzwischen selbst einräumt, dass auch Cascading Style-Sheets eine ebenso wichtige Rolle spielt, ist Ajax heute mehr als Begriff denn als Akronym zu verstehen (Garrett anlässlich der reboot8 im Juni 2006 in Kopenhagen). ist ein ausgefeiltes Interaktionsmodell im Browser möglich geworden, das über die ursprünglichen HTML-Formularelemente weit hinaus geht. Die Vergabe von Tags ist damit derart in den Interaktionsfluss der Web-Anwendungen integriert worden, dass sie in nennenswertem Umfang stattfinden kann, ohne den Anwender aus seinem augenblicklichen Kontext heraus zu reißen.
Somit kann Tagging zum leistungsfähigen Instrument der Informationsablage und des Retrieval werden. Der Nutzen ist jedem schnell einsichtig, da die Visualisierung der Tag-Wolken neue Strukturen aufdeckt und Erkenntnisse liefert. Der Community-Gedanke ist eine weitere Motivation, die diesen Effekt noch verstärkt.
Ausblick
Da Tagging als recht junges Element in der Mensch-Computer-Interaktion noch nicht voll zur Entfaltung gekommen ist, verbirgt sich hierin ein Potenzial für den Umgang mit Informationen im Computer an sich. Ohne das Internet wäre die qualitativ neue Ebene sozialer Tagging-Systeme, die die Attributvergabe der Nutzer einer Website zu einer gemeinsamen Tag-Datenbasis aggregieren, nicht möglich.
Wünschenswert wären aber zum Beispiel Schnittstellen zwischen den Tagging-Systemen der unterschiedlichen Plattformen. In der derzeitigen Situation muss sich nämlich der Anwender erst entscheiden, welche Art von digitalen Daten er taggen will oder in welchem Datentyp er zu recherchieren gedenkt – Bookmarks, Blogs, Filme, Musik, etc. – bevor er Zugriff auf die eigentlichen Tags bekommt. (Wie würden Sie für einen Artikel über Wolfgang Amadeus Mozart recherchieren?). Diese Abhängigkeit vom Datentyp erinnert doch sehr stark an die Diskussion Applikations-zentriertes Modell vs. Dokumenten-zentrierten Modell beim Entwurf der Desktop-Systeme vor einem Vierteljahrhundert.
Eine Unabhängigkeit vom Datenformat könnte auch die Einbeziehung der Desktop-Dokumente ermöglichen, für die heute noch die Ordnerstruktur das vorgegebene Mittel sind.
Aber gerade das schnelle und bequeme Auffinden von Information und Strukturen im digitalen Raum setzt einen kompetent bewertenden und souveränen Nutzer voraus, der sich über die Spuren, die er selbst im Netz hinterlässt bewusst sein sollte. Persönliche Tag-Wolken sind unter Umständen für alle Welt einsehbar und können damit ein öffentliches Bild des Anwenders zeigen, das ihm selbst nicht recht sein muss. Und auch der Umgang mit kollektiven Filtern der Web-Dienste erfordert ein hohes Maß an Medienkompetenz, um nicht der Versuchung zu erliegen, Informationsquellen außer Acht zu lassen, nur weil sie nicht über das jeweilige Online-Portal oder eine elektronische Suchmaschine erschlossen sind, oder gar das eigene Denken einer vermeintlichen Schwarmintelligenz unterzuordnen.
Literatur
- Cooper, A.: About Face: The Essentials of User Interface Design. Foster City, CA: IDG Books, 1995
- Lotter, W.: Elementarteilchen. Brand Eins 2 (2007) 52-61
- Merholz, P.; Starmer, S.; Surla, S.; McMullin, J.; Reiss, E.: Annual Report, 2004-05, The Information Architecture Institute.
iainstitute.org/news/000464.php (Letzter Zugriff: 1.2.2007) - O’Reilly, T.: What Is Web 2.0 – Design Patterns and Business Models for the Next Generation of Software. 2005.
www.oreillynet.com/pub/a/oreilly/tim/news/2005/09/30/what-is-web-20.html (Letzter Zugriff: 1.2.2007) - Weinberger, D.: What’s Up with Knowledge? Opening Keynote zur 7th Information Architecture Summit 2006.
iasummit.org/2006/conferencedescrip.htm (Letzter Zugriff: 1.2.2007) - Zarkon, R.H.: Hobbes' Internet Timeline v10.2, 2011. www.zakon.org/robert/internet/timeline/ (Letzter Zugriff: 27.8.2012)
à propos
- Taxonomien und Folksonomien – Tagging als neues HCI-Element, UP06 Workshop zur Mensch und Computer 2006, Gelsenkirchen
- Tagging – ein sozialer Tag-Traum? Keynote zum GMW Workshop 2008, Tübingen
- Tag-Wolke für meine Website
- Thomas Vander Wal (2024): The Fog of Complexity