What is hypertext? As the smallest common denominator it can be said that hypertext is text, distributed to a set of discrete sections, with referential links in between.
According to Ted Nelson, hypertext frees the author of the obligation to create sequential text. In some cases it might be more adequate to the topic to choose a form of description that is not necessarily linear or hierarchical. Complex relations are better represented by a network of associated ideas. On the other hand the reader gains autonomy over the text as she is free to decide whilst reading where to proceed in the text when a hyperlink marker shows up.** A footnote is a classical form of a hyperlink. It’s up to the reader to read – as you have just done – or to skip it. In this sense hypertext can be seen as the “generalized footnote”, a metaphor taken from Jakob Nielsen’s book Hypertext & Hypermedia [Nielsen 90, p. 2].
A third dimension of hypertext is the possibility to rearrange existing material according to ones personal reflections on it. A hypertext-aware computer system can be a helpful tool to support the human ability to think – Doug Engelbart would say «to augment the human intellect».
2.1 Historical Overview
The history of hypertext has seen many different systems. Just a few of them can be presented in this section. A more comprehensive overview has been compiled by Jakob Nielsen in Hypertext and Hypermedia [Nielsen 90], respectively in the extended edition Multimedia and Hypertext [Nielsen 95]. Many details are taken from this source as well as from Elements of Hypermedia Design by Peter Gloor [Gloor 97] and from James Gillies’ and Robert Cailliau’s history on How the Web was Born [Gillies/Cailliau 2000]. Another source about hypertext is the hypertext Hypertext Hands-On! It is written and published by Ben Shneiderman and Greg Kearsley using their own hypertext system Hyperties in 1989. [Shneiderman/Kearsley 89].
The trip back in time starts more than 50 years ago. As We May Think is an article by Vannevar Bush (*1890 †1974), that was published in 1945 [Bush 45]. During World War II Bush is Director of the Office of Scientific Research and Development and in consequence the highest-ranking scientific administrator in the US war effort. He coordinates the activities of about six thousand American scientists and is especially in charge of the Manhattan Project that develops the atomic bomb [Klaphaak 96], [Hegland 2000].
As We May Think is the description of a hypothetical system called Memex (cf. 2.1.1), that supports scientists in their daily work. Bush recognizes the situation that coping with an increasing number of scientific publications becomes a rising problem. Memex should archive all scientific journals and reports as well as all writings of the owner of the system on microfilm.
To keep track of all the data Memex offers to define trails through the stored articles. This creates sequences of pages that belong to a given chain of thought. Vannevar Bush points out, that classical filing methods like sorting by alphabetical order are artificial and do not correspond to the way humans think. A more natural approach would be to put the articles into context. A set of meaningful relations between the documents that map the associative style of the human mind.
The influence of Bush’s article on the field of hypertext cannot be underestimated. Memex’ trails count as the first sketch for the concept of hyperlinks.
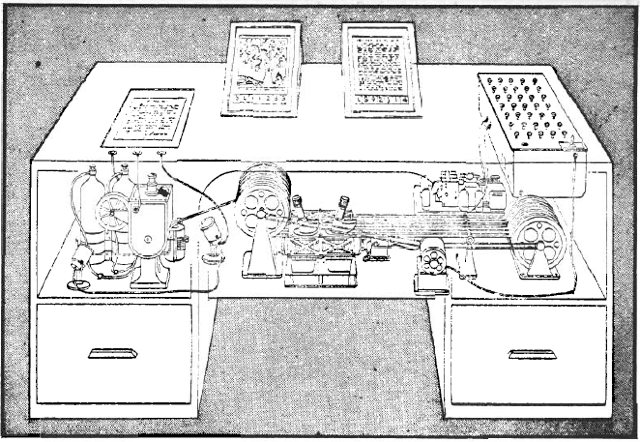
Fig. 2.1 Memex, as it was illustrated for LIFE Magazine, 1945. The desk contains two main microfilm projectors and mechanical apparatus to retrieve the pages for a given trail.
The term hypertext was coined by Ted Nelson in the early 1960s. In his understanding hypertext stands for non-sequential writing. To the reader hypertext offers several different branches to assemble the meaning behind the written text. It is not possible to articulate orally two ideas at the same time. They have to be put in sequence to be properly told to the recipient of the message. The linear structure of printed books is just deduced from the linear structure of speech. The way such coherent texts are created by humans is far from linear. It is associative, as also Vannevar Bush has said twenty years before. Computers should be used to support the deep structure of thinking. Hypertext should free the author from the need of linearizing her text.
Xanadu (cf. 2.1.2) is Ted Nelson’s own attempt for a hypertext system. It is more of a framework than a working program, although several aspects of Xanadu have exceeded the level of working prototypes. The incontestable merits of Xanadu is the influence it took on nearly all hypertext systems to come.
The Advanced Research Project Agency (ARPA) was established by the US Department of Defence in 1958 as a direct response to the Sputnik shock a year before. While NASA’s brief was the mission to space, ARPA would initiate projects that had the chance of boosting America’s defence-related technologies. The Information Processing Techniques Office (IPTO) was established in 1962. The goal of this ARPA office was to devise new utilization of computers other than plain computation. Joseph Licklider, the first director of IPTO, set the direction towards an «Intergalactic Computer Network» [Segaller 98, p. 39]. Bob Taylor, then a manager at NASA, shared Licklider’s vision of the network. As Licklider’s successor he devised the ARPAnet, the predecessor of the Internet today. They finally reached their goal to connect the first four nodes by end of 1969.** Nerds 2.0.1 by Stephen Segaller gives an overview to the history of the Internet [Segaller 98]. The first four nodes of the ARPAnet are installed in 1969. The sites are the University of Los Angeles (September 1), SRI (October 1), the University of Santa Barbara (November 1) and the University of Utah (December 1). The fifth node is the company BBN itself, that built the Interface Message Processors (IMP) to connect the local mini computers to the net.
After Doug Engelbart had finished his reportAugmenting Human Intellect: A Conceptual Framework in 1962 [Engelbart 62], funding from NASA and ARPA – later also from Air Force’s RADC – grew the Augmentation Research Center at Stanford Research Institute (SRI-ARC). His research agenda exposes the design of a system that augments human mental abilities. An essential condition to reach this goal is to enhance the input and output channels of the computer. Engelbart realized, that computer screens can and should be used to display text. Until the late 1950s computer monitors are merely used to display radar data for the air-defence system SAGE [Friedewald 99, p. 95]. Engelbart felt the user should directly interact with the computer system, without dealing with punched-cards, teletype or any other means of batch processing.
The system NLS (cf. 2.1.3) was named after the literal meaning of being on-line with the computer – the oN-Line System – where “on-line” was not used with the sense of today to have a system connected to the Internet. There was no Internet yet. The meaning of on-line in the 1960s was to use the machine interactively. For SRI this was made possible by the use of one of the first time-sharing computers.
The public highlight of SRI was the presentation of NLS at the Fall Joint Computer Conference (FJCC) in San Francisco at December 9, 1968. This session is often referred to as “the mother of all demos”. Doug Engelbart and his team present the mouse, windows, interactive text editing, video conferencing and last not least the hypertext capabilities of NLS. In fact NLS is the first hypertext system that became operational.
The second hypertext system is HES (cf. 2.1.4), which stands for Hypertext Editing System. It was developed by Andries van Dam and Ted Nelson at Brown University in 1967 on an IBM/360 Model 50 mainframe within a 128K partition of memory. HES was actually used by NASA to write the documentation for the Apollo missions [van Dam 87].
After van Dam has witnessed the NLS presentation at FJCC he started the development of a new File Retrieval and Editing System. The design goal of FRESS (cf. 2.1.4) was to take the best from NLS and HES, and to overcome some limitations of the prior hypertext systems.
Other historical overviews do not mention Smalltalk (cf. 2.1.5) as a hypertext system. In this discourse it should not only be discussed as an important step for graphical user interfaces; Smalltalk also has qualities that make it worth to look at it from the perspective of hypertext. Smalltalk is a programming language that was invented and developed by Alan Kay and Dan Ingalls at Xerox PARC in the early 1970s. It stands in the tradition of Simula, the first object-oriented programming language. The structural similarity between referencing objects and hyperlinking will further be discussed in this chapter.
The 1980s was the decade when numerous hypertext systems were created and presented to the public. Workstations and Personal Computers came into widespread use. The IBM-PC with the text-oriented operating system DOS was first marketed in 1981. The first successful computer with a graphical user interface is Apple’s Macintosh – introduced in 1984.
NoteCards (cf. 2.1.6) is originally a research project at Xerox PARC starting in the early-1980s. It uses a physical card metaphor; i.e. each card displays its content in a separate window. The system is designed to support information-analysis tasks, like reading, interpretation, categorization and technical writing [Shneiderman/Kearsley 89]. For that reason the focus lies on structuring and editing information compared to a more browsing and reading focus of Hyperties and Guide that run on less powerful personal computers. Consequently a special browser card displays an overview graph to illustrate the connections between the cards.
NoteCards is fully integrated with the InterLisp environment for Xerox workstations. This means that it is highly customizable for the skilled user.** Shneiderman and Kearsley give the following example: A LISP program can be written that collects all bibliographic references, creates a card for each reference and connects all cards that cite the reference with the new bibliographic card. [Shneiderman/Kearsley 89]
The field of online documentation is tackled by Symbolics Inc. Since 1985 the entire user manual for Symbolics’ workstations has been delivered as an electronic edition. The applications program Document Examiner (cf. 2.1.7) is the browser – the corresponding editor Concordia is used to create a hypertext that consists of approximately 10,000 nodes and 23,000 links. According to Janet Walker, the designer of the system, this size corresponds to about 8,000 pages for a printed edition (Document Examiner: Delivery Interface for Hypertext Documents [Walker 87, p. 307]).
Document Examiner and Concordia are implemented like NoteCards in LISP. This is no surprise, since the entire operating system for the Symbolics LISP Machine is also done in LISP.
Ben Shneiderman starts Hyperties (cf. 2.1.8) as a research project at HCIL around 1983. He takes a very simplified approach in browsing the hypertext in order to attract first time users. Especially museums discover the application of hypertext to support their exhibitions. For example “King Herod’s Dream” at the Smithsonian Museum of Natural History in 1988 or an exhibition about the history of Holocaust at the Museum of Jewish Heritage in New York [Shneiderman/Kearsley 89, p. 33]. A commercial version of Hyperties runs on MS-DOS and uses just a plain text screen. No mouse is necessary to operate the program, although it is possible to click on hyperlinks if a mouse or a touch screen is present.
The development of Guide (cf. 2.1.9) starts in 1982 at the University of Kent. Peter Brown has a first version running on a workstation one year later. In 1984 the British company Office Workstations Ltd. (OWL) gets interested and releases a Macintosh version in 1986. Soon thereafter Guide is ported to IBM-PCs. Guide becomes the first popular commercial hypertext system. It shall be noted here that OWL offers also the option to import SGML files into Guide’s hypertext format.
Bill Atkinson was one of the school kids that had contact with Xerox Alto computers and Smalltalk during the 1970s. Adele Goldberg and Alan Kay of Xerox Parc’s Learning Research Group (LRG) conducted a lot of courses for children to evaluate their conception of interaction principles. During the 1980s Bill Atkinson was working for Apple Computer. He was member of the team that designs the Lisa Desktop Manager, he created MacPaint and in 1987 HyperCard (cf. 2.1.10). HyperCard uses a cards metaphor. Each card has the same size to fit on the original 9" Macintosh screen. The cards are organized in stacks where the user can flip through. The hypertext functionality comes in as HyperCard is combined with HyperTalk, an easy to learn programming language. A rectangular region can be made sensitive for mouse clicks with a tiny piece of HyperTalk. Most of the time, a click triggers the display of another card in the stack.
The wide acceptance of HyperCard was based on a free copy that was bundled with every Macintosh starting in 1987. For many people, it is their first contact with the concept of hypertext.
Storyspace (cf. 2.1.11) was developed in 1990 by Mark Bernstein. It was initially released for Macintosh only, but a port to Windows also exists. Storyspace is much better suited for writing and reading hypertext than HyperCard is, in that it supports text links rather than just rectangular areas on top of the text layer, that need to be updated if the text underneath moves. Hyperlinks do not have to be coded, they are created and directly manipulated with the mouse.
Several scientific texts have been written with Storyspace, because the diagram mode visually reveals the logical structure of arguments. Poets use it to write interactive fiction and poems. This is remarkable as non-technicians consort with the field of computer hypertext for the first time.
All of the presented hypertext systems – with the notable exception of Xanadu – are closed hypertext systems. All hypertexts are solitary. They are isolated from each other. Hyperlinking from one hyperdocument into another on the same machine is not possible – even when the creating applications program is the same. Hyperlinking between hypertexts on different computers is utopian. And by the way it is not a matter of missing wires. Nearly all local sites have their PCs connected to a local area network (LAN). And the Internet – then the ARPAnet – is operational since 1969 and hits the mark of 100,000 connected hosts by 1989.** ARPAnet switched to TCP/IP in 1983. Hence the Internet was born. The number of nodes increases rapidly: 1,000 in 1984, 10,000 in 1987, 100,000 in 1989; 1,000,000 in 1992. (Timeline in Nerds 2.0.1 [Segaller 98]) Electronic mail, newsgroups, FTP and remote login are the main services on the net. But hypertext systems that make use of the infrastructure are yet to be deployed.
Intermedia and Microcosm aim to bridge the border between programs and different file formats. Intermedia (cf. 2.1.12) was developed – once again – at Brown University in 1985. Its advanced concept to administrate links between documents of arbitrary programs is unique for the time. Intermedia is a model how to extend the operating system to provide a common API for all application programs to share linking information with each other. Unfortunately Intermedia did not get much attention because its target platform is A/UX, a Unix derivate for Macintosh that was not in widespread use.
Microcosm (cf. 2.1.13) is a research project at the University of Southampton. Like Intermedia five years before, Microcosm is designed around the idea that material of diverse sources and formats should be tied together into one hypertext. To achieve this goal links have to be separated from the documents. They are stored and maintained in special link databases. In contrast to Intermedia, Microcosm plays the active role in gathering the necessary data out of the documents. For each topic it stores data on which documents contain information about it and also where inside the documents the information is located. This elaborated conception of links can be seen more as a kind of Memex’ trails than simple one-to-one links. Given this structure dynamic linking becomes possible. This means that links can be associated with generic text strings. Wherever this string shows up a link is placed automatically. This has the effect that documents that are imported for the first time into Microcosm can have links immediately.
Microcosm becomes the prototype of an Open Hypermedia System (OHS) and is under continuous research and development until today.
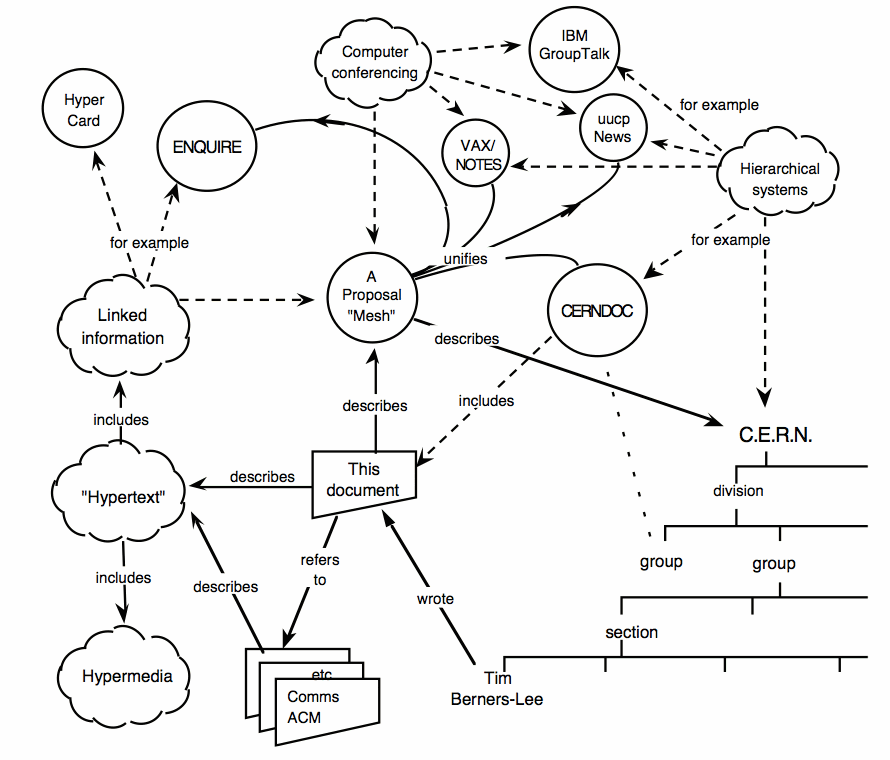
Fig. 2.2 Tim Berners-Lee’s diagram for the World Wide Web, then named “Mesh”, 1989
The World Wide Web (cf. 2.1.14) was born at the international laboratory for particle physics CERN in Geneva. CERN’s scientific community is made up of several thousand people. They use a wide variety of different hardware and software. Keeping track of this organism is difficult; exchanging documents electronically is even more difficult because the incompatibilities between the systems are manifold. Furthermore many physicist are not located in Geneva itself. They work remotely from all over the world.
Tim Berners-Lee and Robert Cailliau propose a distributed hypertext system to solve these problems. Information Management: A Proposal is written in 1989 [Berners-Lee 89], WorldWideWeb: Proposal for a HyperText Project a year later [Berners-Lee/Cailliau 90]. The first Web server becomes operational by end of 1990 with the URL address
Fig. 2.2 is taken from the cover of Berners-Lee’s proposal. It depicts one of the reasons for the success of the World Wide Web. The Web unifies existing information networks as early Web browsers are capable of accessing services like UUCP newsgroups, FTP and WAIS. Just one applications program is needed to access all the diverse sources – a boost in ease of use compared to the many different programs on many different platforms that were necessary before.
Furthermore the Web builds on existing technology, i.e. the hypertext transfer protocol (HTTP) builds on top of TCP/IP. Web pages are encoded with the hypertext markup language (HTML), a simple application of SGML, with the intended side effect that only ASCII characters are used. This makes it easy to edit and transfer HTML files with existing software between all platforms.
During the following years browsers are developed for all main operating systems, i.e. Mosaic for X-Windows by Marc Andreessen at NCSA released early in 1993, Macintosh and Windows versions follow by November the same year. Ten years after the first Web server has started at CERN the number of Web servers reaches ten million world wide.** The mark of 10 million is passed in February 2000. In July 2001 we have reached over 30 million Web servers. Source: Hobbes’ Internet Timeline v5.4 [Zakon 2001].
The genesis of the Web is described comprehensively by Tim Berners-Lee in Weaving the Web [Berners-Lee 99] and by Robert Cailliau in How the Web was Born [Gillies/Cailliau 2000].
Finally Hyper-G (cf. 2.1.15). This project starts also in 1989 at Graz University of Technology. Hermann Maurer and his team aim for a kind of networked version of Microcosm. Many of the flaws of the Web are identified and addressed. But when Hyper-G was presented in 1995 it was too late to get momentum for the new product. The Web was more exploding than growing and left no chance for Hyper-G. At least it will become interesting to contrast the World Wide Web with the competing approach of Hyper-G, respectively with HyperWave as the commercial version is named.
The following sections will take a closer look at the hypertext systems presented so far. The main focus lies on the question of what compelling concepts and features have been lost on the way to the predominant hypertext system World Wide Web.
![]() For a free PDF version of Vision and Reality of Hypertext and Graphical User Interfaces (122 pages), send an e-mail to:
For a free PDF version of Vision and Reality of Hypertext and Graphical User Interfaces (122 pages), send an e-mail to:
![]() mprove@acm.org I’ll usually respond within a day. [privacy policy]
mprove@acm.org I’ll usually respond within a day. [privacy policy]
Incoming Links
CMPS183 Spring 2010: Reading, Jack Baskin School of Engineering